-
1 независимо от того , когда
Большой англо-русский и русско-английский словарь > независимо от того , когда
-
2 no matter when
Большой англо-русский и русско-английский словарь > no matter when
-
3 no matter
независимо от того; безразлично -
4 no matter when
there comes a time when — приходит время, когда
when I am out of here … — когда я уеду отсюда …
Синонимический ряд:whenever (adj.) any moment; any time; at any moment; at your convenience; when you will; whenever -
5 when
1. n время; датаhe came a week ago, since when he has had no rest — он вернулся неделю назад и с того времени не отдыхал
when Queen Anne was alive — в незапамятные времена;
there comes a time when — приходит время, когда
2. adv когда?3. adv когда, которыйthe day when I met you — день, когда я вас встретил
say when — скажи, когда довольно
4. cj (одновременное действие) когда; когда бы ниwhen he listens to music, he falls asleep — он засыпает, когда слушает музыку
it was ten minutes to nine when he returned — когда он вернулся, было уже без десяти девять
find out when he will come — разузнай, когда он придёт
5. cj после того, как; как только; когдаyou can go when the work is done — когда работа будет сделана, можете идти
hardly … when — лишь только …, как
up to the date when — до того дня, когда
6. cj затем; тогда; когдаhe remained in the army until 1916, when he left the service — он оставался в армии до 1916 а затем ушёл в отставку
when I am out of here … — когда я уеду отсюда …
7. cj хотя; когда как; несмотря на то, чтоthey built the bridge in three months when everyone thought it would take a year — они построили мост за три месяца, хотя все думали, что на это уйдёт год
8. cj если, разhow convince him when he will not listen? — как убедить его, если он и слушать не хочет?
Синонимический ряд:1. as soon as (other) as soon as; directly; immediately; once2. at what time (other) at that moment; at what time; at which instant; at which moment; how long ago; how soon; in the event that; just as soon as; on what occasion3. then (other) again; anon; then4. while (other) at the same time as; at the time; during the time that; during this time; just after; just as; meanwhile; while; whilst -
6 accident year experience
страх. статистика [данные\] по году происшествия [убытка\]*, практика года происшествия [убытка\]* (статистика по величине страховых премий, страховым выплатам и другая информация о финансовых операциях страховщика, связанных со страховыми случаями, произошедшими в течение анализируемого двенадцатимесячного периода, независимо от того, когда было сообщено о факте наступления страхового случая и была произведена выплата страховки; напр., для 2005 г. в такую статистику попадет информация, связанная со всеми страховыми событиями, произошедшими с 01.01.2005 по 31.12.2005, независимо от того, осуществлена ли выплата страховки)Syn:See:Англо-русский экономический словарь > accident year experience
-
7 calendar year experience
страх. статистика [данные\] по календарному году*, практика календарного года* (статистика о финансовых операциях страховщика, учитывающая все операции, произведенные в определенном календарном году, независимо от того, когда был выдан страховой полис или произошел страховой случай, в связи с которым эта операция был осуществлена; напр., если в 1999 г. было произведено изменение страховых резервов страховщика в связи со страховым случаем, произошедшим несколькими годами ранее, то сведения об этом изменении резервов будут учтены в статистике за 1999 г.)See:Англо-русский экономический словарь > calendar year experience
-
8 occurrence coverage
страх. (страховое) покрытие по происшествию*, покрытие на основе произошедших случаев* (форма страхования ответственности, при которой страховщик обязуется выплачивать страховку по всем требованиям о возмещении материального ущерба или компенсации телесных повреждений, которые были нанесены в результате событий, произошедших в течение срока действия полиса, независимо от того, когда был обнаружен факт нанесения ущерба и предъявлено требование о выплате компенсации)Syn:See: -
9 product uniformity
марк. единообразие продукции [товаров\] (свойство продукции, заключающееся в том, что вся продукция данного вида имеет одинаковые характеристики, такие как внешний вид, качество и т. д., независимо от того, когда тот или иной продукт был произведен)to guarantee product uniformity from batch to batch — гарантировать единообразие продукции от серии к серии
See: -
10 acceptance of losses
альтернатива «выписанным или возобновленным»; все убытки за период действия договора покрываются независимо от того, когда был выписан первоначальный полис -
11 coverage of detected losses
тип договора перестрахования, покрывающего убытки, обнаруженные в течение срока действия договора независимо от того, когда эти убытки понесеныАнгло-русский экономический словарь > coverage of detected losses
-
12 obligations
Банки/Банковские операциисуммарный объем долговых обязательств банку всей совокупности его клиентов, приходящийся на определенный период времени, независимо от того, когда фактические платежи будут произведены -
13 no matter when
no matter when независимо от того, когда -
14 modular data center
модульный центр обработки данных (ЦОД)
-
[Интент]Параллельные тексты EN-RU
[ http://dcnt.ru/?p=9299#more-9299]
Data Centers are a hot topic these days. No matter where you look, this once obscure aspect of infrastructure is getting a lot of attention. For years, there have been cost pressures on IT operations and this, when the need for modern capacity is greater than ever, has thrust data centers into the spotlight. Server and rack density continues to rise, placing DC professionals and businesses in tighter and tougher situations while they struggle to manage their IT environments. And now hyper-scale cloud infrastructure is taking traditional technologies to limits never explored before and focusing the imagination of the IT industry on new possibilities.
В настоящее время центры обработки данных являются широко обсуждаемой темой. Куда ни посмотришь, этот некогда малоизвестный аспект инфраструктуры привлекает все больше внимания. Годами ИТ-отделы испытывали нехватку средств и это выдвинуло ЦОДы в центр внимания, в то время, когда необходимость в современных ЦОДах стала как никогда высокой. Плотность серверов и стоек продолжают расти, все больше усложняя ситуацию для специалистов в области охлаждения и организаций в их попытках управлять своими ИТ-средами. И теперь гипермасштабируемая облачная инфраструктура подвергает традиционные технологии невиданным ранее нагрузкам, и заставляет ИТ-индустрию искать новые возможности.
At Microsoft, we have focused a lot of thought and research around how to best operate and maintain our global infrastructure and we want to share those learnings. While obviously there are some aspects that we keep to ourselves, we have shared how we operate facilities daily, our technologies and methodologies, and, most importantly, how we monitor and manage our facilities. Whether it’s speaking at industry events, inviting customers to our “Microsoft data center conferences” held in our data centers, or through other media like blogging and white papers, we believe sharing best practices is paramount and will drive the industry forward. So in that vein, we have some interesting news to share.
В компании MicroSoft уделяют большое внимание изучению наилучших методов эксплуатации и технического обслуживания своей глобальной инфраструктуры и делятся результатами своих исследований. И хотя мы, конечно, не раскрываем некоторые аспекты своих исследований, мы делимся повседневным опытом эксплуатации дата-центров, своими технологиями и методологиями и, что важнее всего, методами контроля и управления своими объектами. Будь то доклады на отраслевых событиях, приглашение клиентов на наши конференции, которые посвящены центрам обработки данных MicroSoft, и проводятся в этих самых дата-центрах, или использование других средств, например, блоги и спецификации, мы уверены, что обмен передовым опытом имеет первостепенное значение и будет продвигать отрасль вперед.
Today we are sharing our Generation 4 Modular Data Center plan. This is our vision and will be the foundation of our cloud data center infrastructure in the next five years. We believe it is one of the most revolutionary changes to happen to data centers in the last 30 years. Joining me, in writing this blog are Daniel Costello, my director of Data Center Research and Engineering and Christian Belady, principal power and cooling architect. I feel their voices will add significant value to driving understanding around the many benefits included in this new design paradigm.
Сейчас мы хотим поделиться своим планом модульного дата-центра четвертого поколения. Это наше видение и оно будет основанием для инфраструктуры наших облачных дата-центров в ближайшие пять лет. Мы считаем, что это одно из самых революционных изменений в дата-центрах за последние 30 лет. Вместе со мной в написании этого блога участвовали Дэниел Костелло, директор по исследованиям и инжинирингу дата-центров, и Кристиан Белади, главный архитектор систем энергоснабжения и охлаждения. Мне кажется, что их авторитет придаст больше веса большому количеству преимуществ, включенных в эту новую парадигму проектирования.
Our “Gen 4” modular data centers will take the flexibility of containerized servers—like those in our Chicago data center—and apply it across the entire facility. So what do we mean by modular? Think of it like “building blocks”, where the data center will be composed of modular units of prefabricated mechanical, electrical, security components, etc., in addition to containerized servers.
Was there a key driver for the Generation 4 Data Center?Наши модульные дата-центры “Gen 4” будут гибкими с контейнерами серверов – как серверы в нашем чикагском дата-центре. И гибкость будет применяться ко всему ЦОД. Итак, что мы подразумеваем под модульностью? Мы думаем о ней как о “строительных блоках”, где дата-центр будет состоять из модульных блоков изготовленных в заводских условиях электрических систем и систем охлаждения, а также систем безопасности и т.п., в дополнение к контейнеризованным серверам.
Был ли ключевой стимул для разработки дата-центра четвертого поколения?
If we were to summarize the promise of our Gen 4 design into a single sentence it would be something like this: “A highly modular, scalable, efficient, just-in-time data center capacity program that can be delivered anywhere in the world very quickly and cheaply, while allowing for continued growth as required.” Sounds too good to be true, doesn’t it? Well, keep in mind that these concepts have been in initial development and prototyping for over a year and are based on cumulative knowledge of previous facility generations and the advances we have made since we began our investments in earnest on this new design.Если бы нам нужно было обобщить достоинства нашего проекта Gen 4 в одном предложении, это выглядело бы следующим образом: “Центр обработки данных с высоким уровнем модульности, расширяемости, и энергетической эффективности, а также возможностью постоянного расширения, в случае необходимости, который можно очень быстро и дешево развертывать в любом месте мира”. Звучит слишком хорошо для того чтобы быть правдой, не так ли? Ну, не забывайте, что эти концепции находились в процессе начальной разработки и создания опытного образца в течение более одного года и основываются на опыте, накопленном в ходе развития предыдущих поколений ЦОД, а также успехах, сделанных нами со времени, когда мы начали вкладывать серьезные средства в этот новый проект.
One of the biggest challenges we’ve had at Microsoft is something Mike likes to call the ‘Goldilock’s Problem’. In a nutshell, the problem can be stated as:
The worst thing we can do in delivering facilities for the business is not have enough capacity online, thus limiting the growth of our products and services.Одну из самых больших проблем, с которыми приходилось сталкиваться Майкрософт, Майк любит называть ‘Проблемой Лютика’. Вкратце, эту проблему можно выразить следующим образом:
Самое худшее, что может быть при строительстве ЦОД для бизнеса, это не располагать достаточными производственными мощностями, и тем самым ограничивать рост наших продуктов и сервисов.The second worst thing we can do in delivering facilities for the business is to have too much capacity online.
А вторым самым худшим моментом в этой сфере может слишком большое количество производственных мощностей.
This has led to a focus on smart, intelligent growth for the business — refining our overall demand picture. It can’t be too hot. It can’t be too cold. It has to be ‘Just Right!’ The capital dollars of investment are too large to make without long term planning. As we struggled to master these interesting challenges, we had to ensure that our technological plan also included solutions for the business and operational challenges we faced as well.
So let’s take a high level look at our Generation 4 designЭто заставило нас сосредоточиваться на интеллектуальном росте для бизнеса — refining our overall demand picture. Это не должно быть слишком горячим. И это не должно быть слишком холодным. Это должно быть ‘как раз, таким как надо!’ Нельзя делать такие большие капиталовложения без долгосрочного планирования. Пока мы старались решить эти интересные проблемы, мы должны были гарантировать, что наш технологический план будет также включать решения для коммерческих и эксплуатационных проблем, с которыми нам также приходилось сталкиваться.
Давайте рассмотрим наш проект дата-центра четвертого поколенияAre you ready for some great visuals? Check out this video at Soapbox. Click here for the Microsoft 4th Gen Video.
It’s a concept video that came out of my Data Center Research and Engineering team, under Daniel Costello, that will give you a view into what we think is the future.
From a configuration, construct-ability and time to market perspective, our primary goals and objectives are to modularize the whole data center. Not just the server side (like the Chicago facility), but the mechanical and electrical space as well. This means using the same kind of parts in pre-manufactured modules, the ability to use containers, skids, or rack-based deployments and the ability to tailor the Redundancy and Reliability requirements to the application at a very specific level.
Посмотрите это видео, перейдите по ссылке для просмотра видео о Microsoft 4th Gen:
Это концептуальное видео, созданное командой отдела Data Center Research and Engineering, возглавляемого Дэниелом Костелло, которое даст вам наше представление о будущем.
С точки зрения конфигурации, строительной технологичности и времени вывода на рынок, нашими главными целями и задачами агрегатирование всего дата-центра. Не только серверную часть, как дата-центр в Чикаго, но также системы охлаждения и электрические системы. Это означает применение деталей одного типа в сборных модулях, возможность использования контейнеров, салазок, или стоечных систем, а также возможность подстраивать требования избыточности и надежности для данного приложения на очень специфичном уровне.Our goals from a cost perspective were simple in concept but tough to deliver. First and foremost, we had to reduce the capital cost per critical Mega Watt by the class of use. Some applications can run with N-level redundancy in the infrastructure, others require a little more infrastructure for support. These different classes of infrastructure requirements meant that optimizing for all cost classes was paramount. At Microsoft, we are not a one trick pony and have many Online products and services (240+) that require different levels of operational support. We understand that and ensured that we addressed it in our design which will allow us to reduce capital costs by 20%-40% or greater depending upon class.
Нашими целями в области затрат были концептуально простыми, но трудно реализуемыми. В первую очередь мы должны были снизить капитальные затраты в пересчете на один мегаватт, в зависимости от класса резервирования. Некоторые приложения могут вполне работать на базе инфраструктуры с резервированием на уровне N, то есть без резервирования, а для работы других приложений требуется больше инфраструктуры. Эти разные классы требований инфраструктуры подразумевали, что оптимизация всех классов затрат имеет преобладающее значение. В Майкрософт мы не ограничиваемся одним решением и располагаем большим количеством интерактивных продуктов и сервисов (240+), которым требуются разные уровни эксплуатационной поддержки. Мы понимаем это, и учитываем это в своем проекте, который позволит нам сокращать капитальные затраты на 20%-40% или более в зависимости от класса.For example, non-critical or geo redundant applications have low hardware reliability requirements on a location basis. As a result, Gen 4 can be configured to provide stripped down, low-cost infrastructure with little or no redundancy and/or temperature control. Let’s say an Online service team decides that due to the dramatically lower cost, they will simply use uncontrolled outside air with temperatures ranging 10-35 C and 20-80% RH. The reality is we are already spec-ing this for all of our servers today and working with server vendors to broaden that range even further as Gen 4 becomes a reality. For this class of infrastructure, we eliminate generators, chillers, UPSs, and possibly lower costs relative to traditional infrastructure.
Например, некритичные или гео-избыточные системы имеют низкие требования к аппаратной надежности на основе местоположения. В результате этого, Gen 4 можно конфигурировать для упрощенной, недорогой инфраструктуры с низким уровнем (или вообще без резервирования) резервирования и / или температурного контроля. Скажем, команда интерактивного сервиса решает, что, в связи с намного меньшими затратами, они будут просто использовать некондиционированный наружный воздух с температурой 10-35°C и влажностью 20-80% RH. В реальности мы уже сегодня предъявляем эти требования к своим серверам и работаем с поставщиками серверов над еще большим расширением диапазона температур, так как наш модуль и подход Gen 4 становится реальностью. Для подобного класса инфраструктуры мы удаляем генераторы, чиллеры, ИБП, и, возможно, будем предлагать более низкие затраты, по сравнению с традиционной инфраструктурой.
Applications that demand higher level of redundancy or temperature control will use configurations of Gen 4 to meet those needs, however, they will also cost more (but still less than traditional data centers). We see this cost difference driving engineering behavioral change in that we predict more applications will drive towards Geo redundancy to lower costs.
Системы, которым требуется более высокий уровень резервирования или температурного контроля, будут использовать конфигурации Gen 4, отвечающие этим требованиям, однако, они будут также стоить больше. Но все равно они будут стоить меньше, чем традиционные дата-центры. Мы предвидим, что эти различия в затратах будут вызывать изменения в методах инжиниринга, и по нашим прогнозам, это будет выражаться в переходе все большего числа систем на гео-избыточность и меньшие затраты.
Another cool thing about Gen 4 is that it allows us to deploy capacity when our demand dictates it. Once finalized, we will no longer need to make large upfront investments. Imagine driving capital costs more closely in-line with actual demand, thus greatly reducing time-to-market and adding the capacity Online inherent in the design. Also reduced is the amount of construction labor required to put these “building blocks” together. Since the entire platform requires pre-manufacture of its core components, on-site construction costs are lowered. This allows us to maximize our return on invested capital.
Еще одно достоинство Gen 4 состоит в том, что он позволяет нам разворачивать дополнительные мощности, когда нам это необходимо. Как только мы закончим проект, нам больше не нужно будет делать большие начальные капиталовложения. Представьте себе возможность более точного согласования капитальных затрат с реальными требованиями, и тем самым значительного снижения времени вывода на рынок и интерактивного добавления мощностей, предусматриваемого проектом. Также снижен объем строительных работ, требуемых для сборки этих “строительных блоков”. Поскольку вся платформа требует предварительного изготовления ее базовых компонентов, затраты на сборку также снижены. Это позволит нам увеличить до максимума окупаемость своих капиталовложений.
Мы все подвергаем сомнениюIn our design process, we questioned everything. You may notice there is no roof and some might be uncomfortable with this. We explored the need of one and throughout our research we got some surprising (positive) results that showed one wasn’t needed.
В своем процессе проектирования мы все подвергаем сомнению. Вы, наверное, обратили внимание на отсутствие крыши, и некоторым специалистам это могло не понравиться. Мы изучили необходимость в крыше и в ходе своих исследований получили удивительные результаты, которые показали, что крыша не нужна.
Серийное производство дата центров
In short, we are striving to bring Henry Ford’s Model T factory to the data center. http://en.wikipedia.org/wiki/Henry_Ford#Model_T. Gen 4 will move data centers from a custom design and build model to a commoditized manufacturing approach. We intend to have our components built in factories and then assemble them in one location (the data center site) very quickly. Think about how a computer, car or plane is built today. Components are manufactured by different companies all over the world to a predefined spec and then integrated in one location based on demands and feature requirements. And just like Henry Ford’s assembly line drove the cost of building and the time-to-market down dramatically for the automobile industry, we expect Gen 4 to do the same for data centers. Everything will be pre-manufactured and assembled on the pad.Мы хотим применить модель автомобильной фабрики Генри Форда к дата-центру. Проект Gen 4 будет способствовать переходу от модели специализированного проектирования и строительства к товарно-производственному, серийному подходу. Мы намерены изготавливать свои компоненты на заводах, а затем очень быстро собирать их в одном месте, в месте строительства дата-центра. Подумайте о том, как сегодня изготавливается компьютер, автомобиль или самолет. Компоненты изготавливаются по заранее определенным спецификациям разными компаниями во всем мире, затем собираются в одном месте на основе спроса и требуемых характеристик. И точно так же как сборочный конвейер Генри Форда привел к значительному уменьшению затрат на производство и времени вывода на рынок в автомобильной промышленности, мы надеемся, что Gen 4 сделает то же самое для дата-центров. Все будет предварительно изготавливаться и собираться на месте.
Невероятно энергоэффективный ЦОД
And did we mention that this platform will be, overall, incredibly energy efficient? From a total energy perspective not only will we have remarkable PUE values, but the total cost of energy going into the facility will be greatly reduced as well. How much energy goes into making concrete? Will we need as much of it? How much energy goes into the fuel of the construction vehicles? This will also be greatly reduced! A key driver is our goal to achieve an average PUE at or below 1.125 by 2012 across our data centers. More than that, we are on a mission to reduce the overall amount of copper and water used in these facilities. We believe these will be the next areas of industry attention when and if the energy problem is solved. So we are asking today…“how can we build a data center with less building”?А мы упоминали, что эта платформа будет, в общем, невероятно энергоэффективной? С точки зрения общей энергии, мы получим не только поразительные значения PUE, но общая стоимость энергии, затраченной на объект будет также значительно снижена. Сколько энергии идет на производство бетона? Нам нужно будет столько энергии? Сколько энергии идет на питание инженерных строительных машин? Это тоже будет значительно снижено! Главным стимулом является достижение среднего PUE не больше 1.125 для всех наших дата-центров к 2012 году. Более того, у нас есть задача сокращения общего количества меди и воды в дата-центрах. Мы думаем, что эти задачи станут следующей заботой отрасли после того как будет решена энергетическая проблема. Итак, сегодня мы спрашиваем себя…“как можно построить дата-центр с меньшим объемом строительных работ”?
Строительство дата центров без чиллеровWe have talked openly and publicly about building chiller-less data centers and running our facilities using aggressive outside economization. Our sincerest hope is that Gen 4 will completely eliminate the use of water. Today’s data centers use massive amounts of water and we see water as the next scarce resource and have decided to take a proactive stance on making water conservation part of our plan.
Мы открыто и публично говорили о строительстве дата-центров без чиллеров и активном использовании в наших центрах обработки данных технологий свободного охлаждения или фрикулинга. Мы искренне надеемся, что Gen 4 позволит полностью отказаться от использования воды. Современные дата-центры расходуют большие объемы воды и так как мы считаем воду следующим редким ресурсом, мы решили принять упреждающие меры и включить экономию воды в свой план.
By sharing this with the industry, we believe everyone can benefit from our methodology. While this concept and approach may be intimidating (or downright frightening) to some in the industry, disclosure ultimately is better for all of us.
Делясь этим опытом с отраслью, мы считаем, что каждый сможет извлечь выгоду из нашей методологией. Хотя эта концепция и подход могут показаться пугающими (или откровенно страшными) для некоторых отраслевых специалистов, раскрывая свои планы мы, в конечном счете, делаем лучше для всех нас.
Gen 4 design (even more than just containers), could reduce the ‘religious’ debates in our industry. With the central spine infrastructure in place, containers or pre-manufactured server halls can be either AC or DC, air-side economized or water-side economized, or not economized at all (though the sanity of that might be questioned). Gen 4 will allow us to decommission, repair and upgrade quickly because everything is modular. No longer will we be governed by the initial decisions made when constructing the facility. We will have almost unlimited use and re-use of the facility and site. We will also be able to use power in an ultra-fluid fashion moving load from critical to non-critical as use and capacity requirements dictate.
Проект Gen 4 позволит уменьшить ‘религиозные’ споры в нашей отрасли. Располагая базовой инфраструктурой, контейнеры или сборные серверные могут оборудоваться системами переменного или постоянного тока, воздушными или водяными экономайзерами, или вообще не использовать экономайзеры. Хотя можно подвергать сомнению разумность такого решения. Gen 4 позволит нам быстро выполнять работы по выводу из эксплуатации, ремонту и модернизации, поскольку все будет модульным. Мы больше не будем руководствоваться начальными решениями, принятыми во время строительства дата-центра. Мы сможем использовать этот дата-центр и инфраструктуру в течение почти неограниченного периода времени. Мы также сможем применять сверхгибкие методы использования электрической энергии, переводя оборудование в режимы критической или некритической нагрузки в соответствии с требуемой мощностью.
Gen 4 – это стандартная платформаFinally, we believe this is a big game changer. Gen 4 will provide a standard platform that our industry can innovate around. For example, all modules in our Gen 4 will have common interfaces clearly defined by our specs and any vendor that meets these specifications will be able to plug into our infrastructure. Whether you are a computer vendor, UPS vendor, generator vendor, etc., you will be able to plug and play into our infrastructure. This means we can also source anyone, anywhere on the globe to minimize costs and maximize performance. We want to help motivate the industry to further innovate—with innovations from which everyone can reap the benefits.
Наконец, мы уверены, что это будет фактором, который значительно изменит ситуацию. Gen 4 будет представлять собой стандартную платформу, которую отрасль сможет обновлять. Например, все модули в нашем Gen 4 будут иметь общепринятые интерфейсы, четко определяемые нашими спецификациями, и оборудование любого поставщика, которое отвечает этим спецификациям можно будет включать в нашу инфраструктуру. Независимо от того производите вы компьютеры, ИБП, генераторы и т.п., вы сможете включать свое оборудование нашу инфраструктуру. Это означает, что мы также сможем обеспечивать всех, в любом месте земного шара, тем самым сводя до минимума затраты и максимальной увеличивая производительность. Мы хотим создать в отрасли мотивацию для дальнейших инноваций – инноваций, от которых каждый сможет получать выгоду.
Главные характеристики дата-центров четвертого поколения Gen4To summarize, the key characteristics of our Generation 4 data centers are:
Scalable
Plug-and-play spine infrastructure
Factory pre-assembled: Pre-Assembled Containers (PACs) & Pre-Manufactured Buildings (PMBs)
Rapid deployment
De-mountable
Reduce TTM
Reduced construction
Sustainable measuresНиже приведены главные характеристики дата-центров четвертого поколения Gen 4:
Расширяемость;
Готовая к использованию базовая инфраструктура;
Изготовление в заводских условиях: сборные контейнеры (PAC) и сборные здания (PMB);
Быстрота развертывания;
Возможность демонтажа;
Снижение времени вывода на рынок (TTM);
Сокращение сроков строительства;
Экологичность;Map applications to DC Class
We hope you join us on this incredible journey of change and innovation!
Long hours of research and engineering time are invested into this process. There are still some long days and nights ahead, but the vision is clear. Rest assured however, that we as refine Generation 4, the team will soon be looking to Generation 5 (even if it is a bit farther out). There is always room to get better.
Использование систем электропитания постоянного тока.
Мы надеемся, что вы присоединитесь к нам в этом невероятном путешествии по миру изменений и инноваций!
На этот проект уже потрачены долгие часы исследований и проектирования. И еще предстоит потратить много дней и ночей, но мы имеем четкое представление о конечной цели. Однако будьте уверены, что как только мы доведем до конца проект модульного дата-центра четвертого поколения, мы вскоре начнем думать о проекте дата-центра пятого поколения. Всегда есть возможность для улучшений.So if you happen to come across Goldilocks in the forest, and you are curious as to why she is smiling you will know that she feels very good about getting very close to ‘JUST RIGHT’.
Generations of Evolution – some background on our data center designsТак что, если вы встретите в лесу девочку по имени Лютик, и вам станет любопытно, почему она улыбается, вы будете знать, что она очень довольна тем, что очень близко подошла к ‘ОПИМАЛЬНОМУ РЕШЕНИЮ’.
Поколения эволюции – история развития наших дата-центровWe thought you might be interested in understanding what happened in the first three generations of our data center designs. When Ray Ozzie wrote his Software plus Services memo it posed a very interesting challenge to us. The winds of change were at ‘tornado’ proportions. That “plus Services” tag had some significant (and unstated) challenges inherent to it. The first was that Microsoft was going to evolve even further into an operations company. While we had been running large scale Internet services since 1995, this development lead us to an entirely new level. Additionally, these “services” would span across both Internet and Enterprise businesses. To those of you who have to operate “stuff”, you know that these are two very different worlds in operational models and challenges. It also meant that, to achieve the same level of reliability and performance required our infrastructure was going to have to scale globally and in a significant way.
Мы подумали, что может быть вам будет интересно узнать историю первых трех поколений наших центров обработки данных. Когда Рэй Оззи написал свою памятную записку Software plus Services, он поставил перед нами очень интересную задачу. Ветра перемен двигались с ураганной скоростью. Это окончание “plus Services” скрывало в себе какие-то значительные и неопределенные задачи. Первая заключалась в том, что Майкрософт собиралась в еще большей степени стать операционной компанией. Несмотря на то, что мы управляли большими интернет-сервисами, начиная с 1995 г., эта разработка подняла нас на абсолютно новый уровень. Кроме того, эти “сервисы” охватывали интернет-компании и корпорации. Тем, кому приходится всем этим управлять, известно, что есть два очень разных мира в области операционных моделей и задач. Это также означало, что для достижения такого же уровня надежности и производительности требовалось, чтобы наша инфраструктура располагала значительными возможностями расширения в глобальных масштабах.
It was that intense atmosphere of change that we first started re-evaluating data center technology and processes in general and our ideas began to reach farther than what was accepted by the industry at large. This was the era of Generation 1. As we look at where most of the world’s data centers are today (and where our facilities were), it represented all the known learning and design requirements that had been in place since IBM built the first purpose-built computer room. These facilities focused more around uptime, reliability and redundancy. Big infrastructure was held accountable to solve all potential environmental shortfalls. This is where the majority of infrastructure in the industry still is today.
Именно в этой атмосфере серьезных изменений мы впервые начали переоценку ЦОД-технологий и технологий вообще, и наши идеи начали выходить за пределы общепринятых в отрасли представлений. Это была эпоха ЦОД первого поколения. Когда мы узнали, где сегодня располагается большинство мировых дата-центров и где находятся наши предприятия, это представляло весь опыт и навыки проектирования, накопленные со времени, когда IBM построила первую серверную. В этих ЦОД больше внимания уделялось бесперебойной работе, надежности и резервированию. Большая инфраструктура была призвана решать все потенциальные экологические проблемы. Сегодня большая часть инфраструктуры все еще находится на этом этапе своего развития.
We soon realized that traditional data centers were quickly becoming outdated. They were not keeping up with the demands of what was happening technologically and environmentally. That’s when we kicked off our Generation 2 design. Gen 2 facilities started taking into account sustainability, energy efficiency, and really looking at the total cost of energy and operations.
Очень быстро мы поняли, что стандартные дата-центры очень быстро становятся устаревшими. Они не поспевали за темпами изменений технологических и экологических требований. Именно тогда мы стали разрабатывать ЦОД второго поколения. В этих дата-центрах Gen 2 стали принимать во внимание такие факторы как устойчивое развитие, энергетическая эффективность, а также общие энергетические и эксплуатационные.
No longer did we view data centers just for the upfront capital costs, but we took a hard look at the facility over the course of its life. Our Quincy, Washington and San Antonio, Texas facilities are examples of our Gen 2 data centers where we explored and implemented new ways to lessen the impact on the environment. These facilities are considered two leading industry examples, based on their energy efficiency and ability to run and operate at new levels of scale and performance by leveraging clean hydro power (Quincy) and recycled waste water (San Antonio) to cool the facility during peak cooling months.
Мы больше не рассматривали дата-центры только с точки зрения начальных капитальных затрат, а внимательно следили за работой ЦОД на протяжении его срока службы. Наши объекты в Куинси, Вашингтоне, и Сан-Антонио, Техас, являются образцами наших ЦОД второго поколения, в которых мы изучали и применяли на практике новые способы снижения воздействия на окружающую среду. Эти объекты считаются двумя ведущими отраслевыми примерами, исходя из их энергетической эффективности и способности работать на новых уровнях производительности, основанных на использовании чистой энергии воды (Куинси) и рециклирования отработанной воды (Сан-Антонио) для охлаждения объекта в самых жарких месяцах.
As we were delivering our Gen 2 facilities into steel and concrete, our Generation 3 facilities were rapidly driving the evolution of the program. The key concepts for our Gen 3 design are increased modularity and greater concentration around energy efficiency and scale. The Gen 3 facility will be best represented by the Chicago, Illinois facility currently under construction. This facility will seem very foreign compared to the traditional data center concepts most of the industry is comfortable with. In fact, if you ever sit around in our container hanger in Chicago it will look incredibly different from a traditional raised-floor data center. We anticipate this modularization will drive huge efficiencies in terms of cost and operations for our business. We will also introduce significant changes in the environmental systems used to run our facilities. These concepts and processes (where applicable) will help us gain even greater efficiencies in our existing footprint, allowing us to further maximize infrastructure investments.
Так как наши ЦОД второго поколения строились из стали и бетона, наши центры обработки данных третьего поколения начали их быстро вытеснять. Главными концептуальными особенностями ЦОД третьего поколения Gen 3 являются повышенная модульность и большее внимание к энергетической эффективности и масштабированию. Дата-центры третьего поколения лучше всего представлены объектом, который в настоящее время строится в Чикаго, Иллинойс. Этот ЦОД будет выглядеть очень необычно, по сравнению с общепринятыми в отрасли представлениями о дата-центре. Действительно, если вам когда-либо удастся побывать в нашем контейнерном ангаре в Чикаго, он покажется вам совершенно непохожим на обычный дата-центр с фальшполом. Мы предполагаем, что этот модульный подход будет способствовать значительному повышению эффективности нашего бизнеса в отношении затрат и операций. Мы также внесем существенные изменения в климатические системы, используемые в наших ЦОД. Эти концепции и технологии, если применимо, позволят нам добиться еще большей эффективности наших существующих дата-центров, и тем самым еще больше увеличивать капиталовложения в инфраструктуру.
This is definitely a journey, not a destination industry. In fact, our Generation 4 design has been under heavy engineering for viability and cost for over a year. While the demand of our commercial growth required us to make investments as we grew, we treated each step in the learning as a process for further innovation in data centers. The design for our future Gen 4 facilities enabled us to make visionary advances that addressed the challenges of building, running, and operating facilities all in one concerted effort.
Это определенно путешествие, а не конечный пункт назначения. На самом деле, наш проект ЦОД четвертого поколения подвергался серьезным испытаниям на жизнеспособность и затраты на протяжении целого года. Хотя необходимость в коммерческом росте требовала от нас постоянных капиталовложений, мы рассматривали каждый этап своего развития как шаг к будущим инновациям в области дата-центров. Проект наших будущих ЦОД четвертого поколения Gen 4 позволил нам делать фантастические предположения, которые касались задач строительства, управления и эксплуатации объектов как единого упорядоченного процесса.
Тематики
Синонимы
EN
Англо-русский словарь нормативно-технической терминологии > modular data center
-
15 switching technology
технология коммутации
-
[Интент]Современные технологии коммутации
[ http://www.xnets.ru/plugins/content/content.php?content.84]Статья подготовлена на основании материалов опубликованных в журналах "LAN", "Сети и системы связи", в книге В.Олифер и Н.Олифер "Новые технологии и оборудование IP-сетей", на сайтах www.citforum.ru и опубликована в журнале "Компьютерные решения" NN4-6 за 2000 год.
- Введение
- Коммутация первого уровня.
- Коммутация второго уровня.
- Коммутация третьего уровня.
- Коммутация четвертого уровня.
- Критерии выбора оборудования, физическая и логическая структура сети
- Качество обслуживания (QoS) и принципы задания приоритетов
- Заключение
Введение
На сегодня практически все организации, имеющие локальные сети, остановили свой выбор на сетях типа Ethernet. Данный выбор оправдан тем, что начало внедрения такой сети сопряжено с низкой стоимостью и простотой реализации, а развитие - с хорошей масштабируемостью и экономичностью.
Бросив взгляд назад - увидим, что развитие активного оборудования сетей шло в соответствии с требованиями к полосе пропускания и надежности. Требования, предъявляемые к большей надежности, привели к отказу от применения в качестве среды передачи коаксиального кабеля и перевода сетей на витую пару. В результате такого перехода отказ работы соединения между одной из рабочих станций и концентратором перестал сказываться на работе других рабочих станций сети. Но увеличения производительности данный переход не принес, так как концентраторы используют разделяемую (на всех пользователей в сегменте) полосу пропускания. По сути, изменилась только физическая топология сети - с общей шины на звезду, а логическая топология по-прежнему осталась - общей шиной.
Дальнейшее развитие сетей шло по нескольким путям:- увеличение скорости,
- внедрение сегментирования на основе коммутации,
- объединение сетей при помощи маршрутизации.
Увеличение скорости при прежней логической топологии - общая шина, привело к незначительному росту производительности в случае большого числа портов.
Большую эффективность в работе сети принесло сегментирование сетей с использованием технология коммутации пакетов. Коммутация наиболее действенна в следующих вариантах:
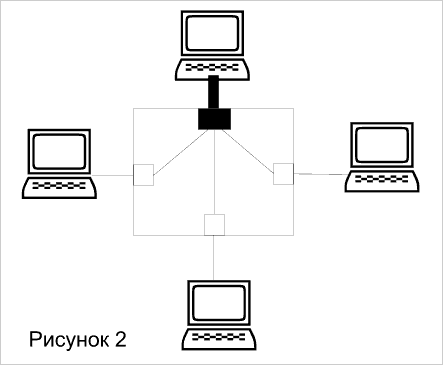
Вариант 1, именуемый связью "многие со многими" – это одноранговые сети, когда одновременно существуют потоки данных между парами рабочих станций. При этом предпочтительнее иметь коммутатор, у которого все порты имеют одинаковую скорость, (см. Рисунок 1).
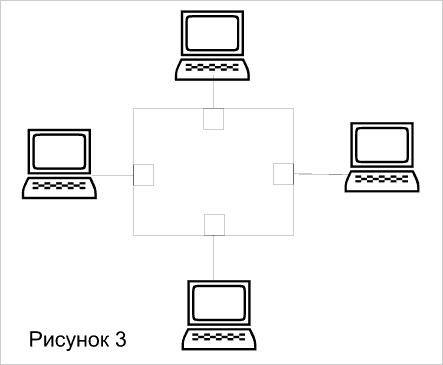
Вариант 2, именуемый связью "один со многими" – это сети клиент-сервер, когда все рабочие станции работают с файлами или базой данных сервера. В данном случае предпочтительнее иметь коммутатор, у которого порты для подключения рабочих станций имеют одинаковую небольшую скорость, а порт, к которому подключается сервер, имеет большую скорость,(см. Рисунок 2).
Когда компании начали связывать разрозненные системы друг с другом, маршрутизация обеспечивала максимально возможную целостность и надежность передачи трафика из одной сети в другую. Но с ростом размера и сложности сети, а также в связи со все более широким применением коммутаторов в локальных сетях, базовые маршрутизаторы (зачастую они получали все данные, посылаемые коммутаторами) стали с трудом справляться со своими задачами.
Проблемы с трафиком, связанные с маршрутизацией, проявляются наиболее остро в средних и крупных компаниях, а также в деятельности операторов Internet, так как они вынуждены иметь дело с большими объемами IP-трафика, причем этот трафик должен передаваться своевременно и эффективно.
С подключением настольных систем непосредственно к коммутаторам на 10/100 Мбит/с между ними и магистралью оказывается все меньше промежуточных устройств. Чем выше скорость подключения настольных систем, тем более скоростной должна быть магистраль. Кроме того, на каждом уровне устройства должны справляться с приходящим трафиком, иначе возникновения заторов не избежать.
Рассмотрению технологий коммутации и посвящена данная статья.Коммутация первого уровня
Термин "коммутация первого уровня" в современной технической литературе практически не описывается. Для начала дадим определение, с какими характеристиками имеет дело физический или первый уровень модели OSI:
физический уровень определяет электротехнические, механические, процедурные и функциональные характеристики активации, поддержания и дезактивации физического канала между конечными системами. Спецификации физического уровня определяют такие характеристики, как уровни напряжений, синхронизацию изменения напряжений, скорость передачи физической информации, максимальные расстояния передачи информации, физические соединители и другие аналогичные характеристики.
Смысл коммутации на первом уровне модели OSI означает физическое (по названию уровня) соединение. Из примеров коммутации первого уровня можно привести релейные коммутаторы некоторых старых телефонных и селекторных систем. В более новых телефонных системах коммутация первого уровня применяется совместно с различными способами сигнализации вызовов и усиления сигналов. В сетях передачи данных данная технология применяется в полностью оптических коммутаторах.Коммутация второго уровня
Рассматривая свойства второго уровня модели OSI и его классическое определение, увидим, что данному уровню принадлежит основная доля коммутирующих свойств.
Определение. Канальный уровень (формально называемый информационно-канальным уровнем) обеспечивает надежный транзит данных через физический канал. Канальный уровень решает вопросы физической адресации (в противоположность сетевой или логической адресации), топологии сети, линейной дисциплины (каким образом конечной системе использовать сетевой канал), уведомления о неисправностях, упорядоченной доставки блоков данных и управления потоком информации.
На самом деле, определяемая канальным уровнем модели OSI функциональность служит платформой для некоторых из сегодняшних наиболее эффективных технологий. Большое значение функциональности второго уровня подчеркивает тот факт, что производители оборудования продолжают вкладывать значительные средства в разработку устройств с такими функциями.
С технологической точки зрения, коммутатор локальных сетей представляет собой устройство, основное назначение которого - максимальное ускорение передачи данных за счет параллельно существующих потоков между узлами сети. В этом - его главное отличие от других традиционных устройств локальных сетей – концентраторов (Hub), предоставляющих всем потокам данных сети всего один канал передачи данных.
Коммутатор позволяет передавать параллельно несколько потоков данных c максимально возможной для каждого потока скоростью. Эта скорость ограничена физической спецификацией протокола, которую также часто называют "скоростью провода". Это возможно благодаря наличию в коммутаторе большого числа центров обработки и продвижения кадров и шин передачи данных.
Коммутаторы локальных сетей в своем основном варианте, ставшем классическим уже с начала 90-х годов, работают на втором уровне модели OSI, применяя свою высокопроизводительную параллельную архитектуру для продвижения кадров канальных протоколов. Другими словами, ими выполняются алгоритмы работы моста, описанные в стандартах IEEE 802.1D и 802.1H. Также они имеют и много других дополнительных функций, часть которых вошла в новую редакцию стандарта 802.1D-1998, а часть остается пока не стандартизованной.
Коммутаторы ЛВС отличаются большим разнообразием возможностей и, следовательно, цен - стоимость 1 порта колеблется в диапазоне от 50 до 1000 долларов. Одной из причин столь больших различий является то, что они предназначены для решения различных классов задач. Коммутаторы высокого класса должны обеспечивать высокую производительность и плотность портов, а также поддерживать широкий спектр функций управления. Простые и дешевые коммутаторы имеют обычно небольшое число портов и не способны поддерживать функции управления. Одним из основных различий является используемая в коммутаторе архитектура. Поскольку большинство современных коммутаторов работают на основе патентованных контроллеров ASIC, устройство этих микросхем и их интеграция с остальными модулями коммутатора (включая буферы ввода-вывода) играет важнейшую роль. Контроллеры ASIC для коммутаторов ЛВС делятся на 2 класса - большие ASIC, способные обслуживать множество коммутируемых портов (один контроллер на устройство) и небольшие ASIC, обслуживающие по несколько портов и объединяемые в матрицы коммутации.
Существует 3 варианта архитектуры коммутаторов:
- переключение (cross-bar) с буферизацией на входе,
- самомаршрутизация (self-route) с разделяемой памятью
- высокоскоростная шина.
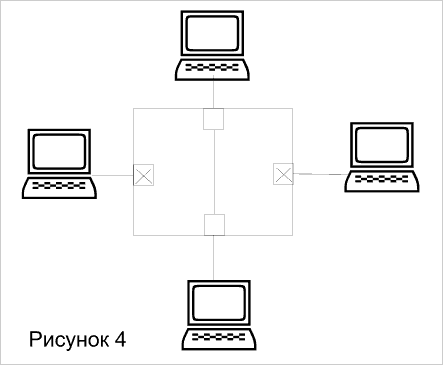
На рисунке 3 показана блок-схема коммутатора с архитектурой, используемой для поочередного соединения пар портов. В любой момент такой коммутатор может обеспечить организацию только одного соединения (пара портов). При невысоком уровне трафика не требуется хранение данных в памяти перед отправкой в порт назначения - такой вариант называется коммутацией на лету cut-through. Однако, коммутаторы cross-bar требуют буферизации на входе от каждого порта, поскольку в случае использования единственно возможного соединения коммутатор блокируется (рисунок 4). Несмотря на малую стоимость и высокую скорость продвижения на рынок, коммутаторы класса cross-bar слишком примитивны для эффективной трансляции между низкоскоростными интерфейсами Ethernet или token ring и высокоскоростными портами ATM и FDDI.
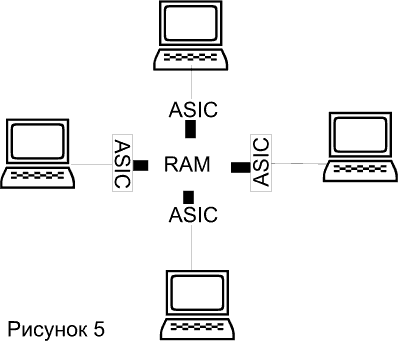
Коммутаторы с разделяемой памятью имеют общий входной буфер для всех портов, используемый как внутренняя магистраль устройства (backplane). Буферизагия данных перед их рассылкой (store-and-forward - сохранить и переслать) приводит к возникновению задержки. Однако, коммутаторы с разделяемой памятью, как показано на рисунке 5 не требуют организации специальной внутренней магистрали для передачи данных между портами, что обеспечивает им более низкую цену по сравнению с коммутаторами на базе высокоскоростной внутренней шины.
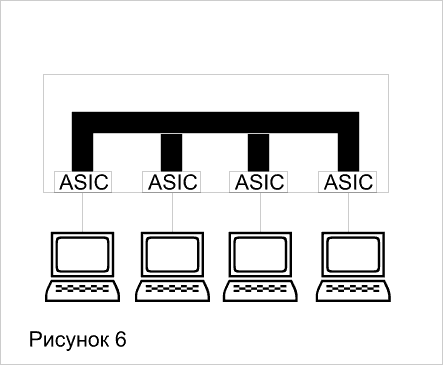
На рисунке 6 показана блок-схема коммутатора с высокоскоростной шиной, связывающей контроллеры ASIC. После того, как данные преобразуются в приемлемый для передачи по шине формат, они помещаются на шину и далее передаются в порт назначения. Поскольку шина может обеспечивать одновременную (паралельную) передачу потока данных от всех портов, такие коммутаторы часто называют "неблокируемыми" (non-blocking) - они не создают пробок на пути передачи данных.
Применение аналогичной параллельной архитектуры для продвижения пакетов сетевых протоколов привело к появлению коммутаторов третьего уровня модели OSI.
Коммутация третьего уровня
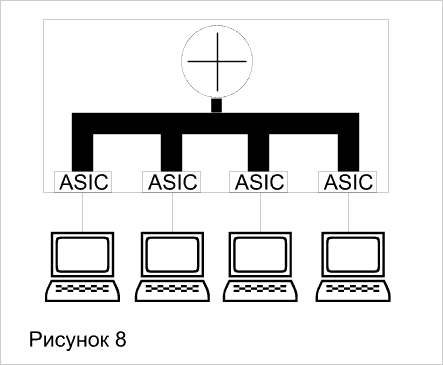
В продолжении темы о технологиях коммутации рассмотренных в предыдущем номера повторим, что применение параллельной архитектуры для продвижения пакетов сетевых протоколов привело к появлению коммутаторов третьего уровня. Это позволило существенно, в 10-100 раз повысить скорость маршрутизации по сравнению с традиционными маршрутизаторами, в которых один центральный универсальный процессор выполняет программное обеспечение маршрутизации.
По определению Сетевой уровень (третий) - это комплексный уровень, который обеспечивает возможность соединения и выбор маршрута между двумя конечными системами, подключенными к разным "подсетям", которые могут находиться в разных географических пунктах. В данном случае "подсеть" это, по сути, независимый сетевой кабель (иногда называемый сегментом).
Коммутация на третьем уровне - это аппаратная маршрутизация. Традиционные маршрутизаторы реализуют свои функции с помощью программно-управляемых процессоров, что будем называть программной маршрутизацией. Традиционные маршрутизаторы обычно продвигают пакеты со скоростью около 500000 пакетов в секунду. Коммутаторы третьего уровня сегодня работают со скоростью до 50 миллионов пакетов в секунду. Возможно и дальнейшее ее повышение, так как каждый интерфейсный модуль, как и в коммутаторе второго уровня, оснащен собственным процессором продвижения пакетов на основе ASIC. Так что наращивание количества модулей ведет к наращиванию производительности маршрутизации. Использование высокоскоростной технологии больших заказных интегральных схем (ASIC) является главной характеристикой, отличающей коммутаторы третьего уровня от традиционных маршрутизаторов. Коммутаторы 3-го уровня делятся на две категории: пакетные (Packet-by-Packet Layer 3 Switches, PPL3) и сквозные (Cut-Through Layer 3 Switches, CTL3). PPL3 - означает просто быструю маршрутизацию (Рисунок_7). CTL3 – маршрутизацию первого пакета и коммутацию всех остальных (Рисунок 8).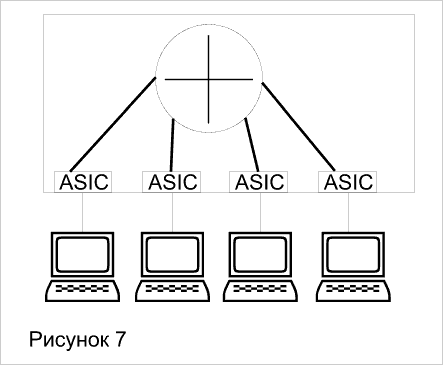
У коммутатора третьего уровня, кроме реализации функций маршрутизации в специализированных интегральных схемах, имеется несколько особенностей, отличающих их от традиционных маршрутизаторов. Эти особенности отражают ориентацию коммутаторов 3-го уровня на работу, в основном, в локальных сетях, а также последствия совмещения в одном устройстве коммутации на 2-м и 3-м уровнях:
- поддержка интерфейсов и протоколов, применяемых в локальных сетях,
- усеченные функции маршрутизации,
- обязательная поддержка механизма виртуальных сетей,
- тесная интеграция функций коммутации и маршрутизации, наличие удобных для администратора операций по заданию маршрутизации между виртуальными сетями.
Наиболее "коммутаторная" версия высокоскоростной маршрутизации выглядит следующим образом (рисунок 9). Пусть коммутатор третьего уровня построен так, что в нем имеется информация о соответствии сетевых адресов (например, IP-адресов) адресам физического уровня (например, MAC-адресам) Все эти МАС-адреса обычным образом отображены в коммутационной таблице, независимо от того, принадлежат ли они данной сети или другим сетям.
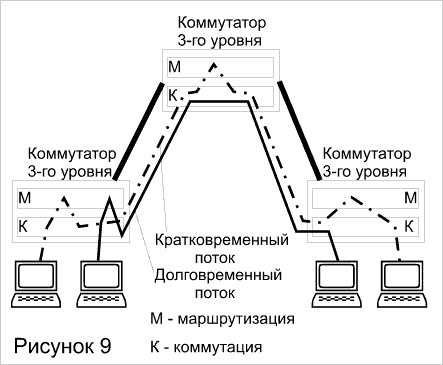
Первый коммутатор, на который поступает пакет, частично выполняет функции маршрутизатора, а именно, функции фильтрации, обеспечивающие безопасность. Он решает, пропускать или нет данный пакет в другую сеть Если пакет пропускать нужно, то коммутатор по IP-адресу назначения определяет МАС-адрес узла назначения и формирует новый заголовок второго уровня с найденным МАС-адресом. Затем выполняется обычная процедура коммутации по данному МАС-адресу с просмотром адресной таблицы коммутатора. Все последующие коммутаторы, построенные по этому же принципу, обрабатывают данный кадр как обычные коммутаторы второго уровня, не привлекая функций маршрутизации, что значительно ускоряет его обработку. Однако функции маршрутизации не являются для них избыточными, поскольку и на эти коммутаторы могут поступать первичные пакеты (непосредственно от рабочих станций), для которых необходимо выполнять фильтрацию и подстановку МАС-адресов.
Это описание носит схематический характер и не раскрывает способов решения возникающих при этом многочисленных проблем, например, проблемы построения таблицы соответствия IP-адресов и МАС-адресов
Примерами коммутаторов третьего уровня, работающих по этой схеме, являются коммутаторы SmartSwitch компании Cabletron. Компания Cabletron реализовала в них свой протокол ускоренной маршрутизации SecureFast Virtual Network, SFVN.
Для организации непосредственного взаимодействия рабочих станций без промежуточного маршрутизатора необходимо сконфигурировать каждую из них так, чтобы она считала собственный интерфейс маршрутизатором по умолчанию. При такой конфигурации станция пытается самостоятельно отправить любой пакет конечному узлу, даже если этот узел находится в другой сети. Так как в общем случае (см. рисунок 10) станции неизвестен МАС-адрес узла назначения, то она генерирует соответствующий ARP-запрос, который перехватывает коммутатор, поддерживающий протокол SFVN. В сети предполагается наличие сервера SFVN Server, являющегося полноценным маршрутизатором и поддерживающего общую ARP-таблицу всех узлов SFVN-сети. Сервер возвращает коммутатору МАС-адрес узла назначения, а коммутатор, в свою очередь, передает его исходной станции. Одновременно сервер SFVN передает коммутаторам сети инструкции о разрешении прохождения пакета с МАС-адресом узла назначения через границы виртуальных сетей. Затем исходная станция передает пакет в кадре, содержащем МАС-адрес узла назначения. Этот кадр проходит через коммутаторы, не вызывая обращения к их блокам маршрутизации. Отличие протокола SFVN компании Cabletron от - описанной выше общей схемы в том, что для нахождения МАС-адреса по IP-адресу в сети используется выделенный сервер.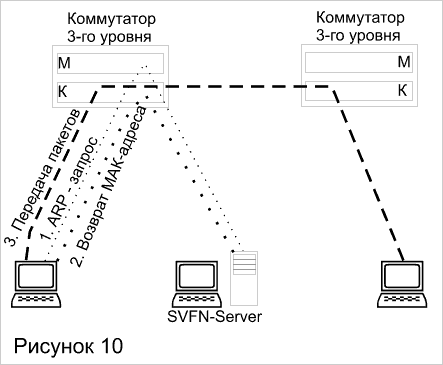
Протокол Fast IP компании 3Com является еще одним примером реализации подхода с отображением IP-адреса на МАС-адрес. В этом протоколе основными действующими лицами являются сетевые адаптеры (что не удивительно, так как компания 3Com является признанным лидером в производстве сетевых адаптеров Ethernet) С одной стороны, такой подход требует изменения программного обеспечения драйверов сетевых адаптеров, и это минус Но зато не требуется изменять все остальное сетевое оборудование.
При необходимости передать пакет узлу назначения другой сети, исходный узел в соответствии с технологией Fast IP должен передать запрос по протоколу NHRP (Next Hop Routing Protocol) маршрутизатору сети. Маршрутизатор переправляет этот запрос узлу назначения, как обычный пакет Узел назначения, который также поддерживает Fast IP и NHRP, получив запрос, отвечает кадром, отсылаемым уже не маршрутизатору, а непосредственно узлу-источнику (по его МАС-адресу, содержащемуся в NHRP-запросе). После этого обмен идет на канальном уровне на основе известных МАС-адресов. Таким образом, снова маршрутизировался только первый пакет потока (как на рисунке 9 кратковременный поток), а все остальные коммутировались (как на рисунке 9 долговременный поток).
Еще один тип коммутаторов третьего уровня — это коммутаторы, работающие с протоколами локальных сетей типа Ethernet и FDDI. Эти коммутаторы выполняют функции маршрутизации не так, как классические маршрутизаторы. Они маршрутизируют не отдельные пакеты, а потоки пакетов.
Поток — это последовательность пакетов, имеющих некоторые общие свойства. По меньшей мере, у них должны совпадать адрес отправителя и адрес получателя, и тогда их можно отправлять по одному и тому же маршруту. Если классический способ маршрутизации использовать только для первого пакета потока, а все остальные обрабатывать на основании опыта первого (или нескольких первых) пакетов, то можно значительно ускорить маршрутизацию всего потока.
Рассмотрим этот подход на примере технологии NetFlow компании Cisco, реализованной в ее маршрутизаторах и коммутаторах. Для каждого пакета, поступающего на порт маршрутизатора, вычисляется хэш-функция от IP-адресов источника, назначения, портов UDP или TCP и поля TOS, характеризующего требуемое качество обслуживания. Во всех маршрутизаторах, поддерживающих данную технологию, через которые проходит данный пакет, в кэш-памяти портов запоминается соответствие значения хэш-функции и адресной информации, необходимой для быстрой передачи пакета следующему маршрутизатору. Таким образом, образуется квазивиртуальный канал (см. Рисунок 11), который позволяет быстро передавать по сети маршрутизаторов все последующие пакеты этого потока. При этом ускорение достигается за счет упрощения процедуры обработки пакета маршрутизатором - не просматриваются таблицы маршрутизации, не выполняются ARP-запросы.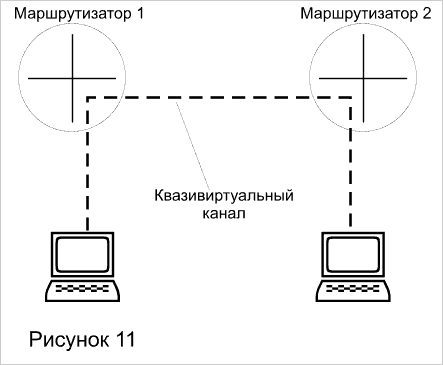
Этот прием может использоваться в маршрутизаторах, вообще не поддерживающих коммутацию, а может быть перенесен в коммутаторы. В этом случае такие коммутаторы тоже называют коммутаторами третьего уровня. Примеров маршрутизаторов, использующих данный подход, являются маршрутизаторы Cisco 7500, а коммутаторов третьего уровня — коммутаторы Catalyst 5000 и 5500. Коммутаторы Catalyst выполняют усеченные функции описанной схемы, они не могут обрабатывать первые пакеты потоков и создавать новые записи о хэш-функциях и адресной информации потоков. Они просто получают данную информацию от маршрутизаторов 7500 и обрабатывают пакеты уже распознанных маршрутизаторами потоков.
Выше был рассмотрен способ ускоренной маршрутизации, основанный на концепции потока. Его сущность заключается в создании квазивиртуальных каналов в сетях, которые не поддерживают виртуальные каналы в обычном понимании этого термина, то есть сетях Ethernet, FDDI, Token Ring и т п. Следует отличать этот способ от способа ускоренной работы маршрутизаторов в сетях, поддерживающих технологию виртуальных каналов — АТМ, frame relay, X 25. В таких сетях создание виртуального канала является штатным режимом работы сетевых устройств. Виртуальные каналы создаются между двумя конечными точками, причем для потоков данных, требующих разного качества обслуживания (например, для данных разных приложений) может создаваться отдельный виртуальный канал. Хотя время создания виртуального канала существенно превышает время маршрутизации одного пакета, выигрыш достигается за счет последующей быстрой передачи потока данных по виртуальному каналу. Но в таких сетях возникает другая проблема — неэффективная передача коротких потоков, то есть потоков, состоящих из небольшого количества пакетов (классический пример — пакеты протокола DNS).
Накладные расходы, связанные с созданием виртуального канала, приходящиеся на один пакет, снижаются при передаче объемных потоков данных. Однако они становятся неприемлемо высокими при передаче коротких потоков. Для того чтобы эффективно передавать короткие потоки, предлагается следующий вариант, при передаче нескольких первых пакетов выполняется обычная маршрутизация. Затем, после того как распознается устойчивый поток, для него строится виртуальный канал, и дальнейшая передача данных происходит с высокой скоростью по этому виртуальному каналу. Таким образом, для коротких потоков виртуальный канал вообще не создается, что и повышает эффективность передачи.
По такой схеме работает ставшая уже классической технология IP Switching компании Ipsilon. Для того чтобы сети коммутаторов АТМ передавали бы пакеты коротких потоков без установления виртуального канала, компания Ipsilon предложила встроить во все коммутаторы АТМ блоки IP-маршрутизации (рисунок 12), строящие обычные таблицы маршрутизации по обычным протоколам RIP и OSPF.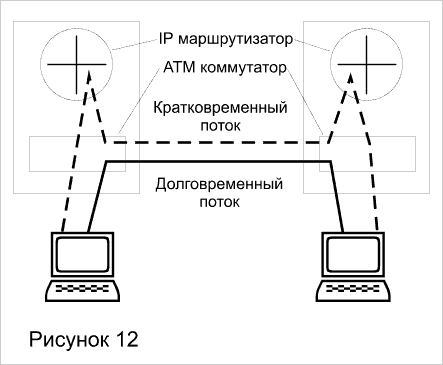
Компания Cisco Systems выдвинула в качестве альтернативы технологии IP Switching свою собственную технологию Tag Switching, но она не стала стандартной. В настоящее время IETF работает над стандартным протоколом обмена метками MPLS (Multi-Protocol Label Switching), который обобщает предложение компаний Ipsilon и Cisco, а также вносит некоторые новые детали и механизмы. Этот протокол ориентирован на поддержку качества обслуживания для виртуальных каналов, образованных метками.
Коммутация четвертого уровня
Свойства четвертого или транспортного уровня модели OSI следующие: транспортный уровень обеспечивает услуги по транспортировке данных. В частности, заботой транспортного уровня является решение таких вопросов, как выполнение надежной транспортировки данных через объединенную сеть. Предоставляя надежные услуги, транспортный уровень обеспечивает механизмы для установки, поддержания и упорядоченного завершения действия виртуальных каналов, систем обнаружения и устранения неисправностей транспортировки и управления информационным потоком (с целью предотвращения переполнения данными из другой системы).
Некоторые производители заявляют, что их системы могут работать на втором, третьем и даже четвертом уровнях. Однако рассмотрение описания стека TCP/IP (рисунок 1), а также структуры пакетов IP и TCP (рисунки 2, 3), показывает, что коммутация четвертого уровня является фикцией, так как все относящиеся к коммутации функции осуществляются на уровне не выше третьего. А именно, термин коммутация четвертого уровня с точки зрения описания стека TCP/IP противоречий не имеет, за исключением того, что при коммутации должны указываться адреса компьютера (маршрутизатора) источника и компьютера (маршрутизатора) получателя. Пакеты TCP имеют поля локальный порт отправителя и локальный порт получателя (рисунок 3), несущие смысл точек входа в приложение (в программу), например Telnet с одной стороны, и точки входа (в данном контексте инкапсуляции) в уровень IP. Кроме того, в стеке TCP/IP именно уровень TCP занимается формированием пакетов из потока данных идущих от приложения. Пакеты IP (рисунок 2) имеют поля адреса компьютера (маршрутизатора) источника и компьютера (маршрутизатора) получателя и следовательно могут наряду с MAC адресами использоваться для коммутации. Тем не менее, название прижилось, к тому же практика показывает, что способность системы анализировать информацию прикладного уровня может оказаться полезной — в частности для управления трафиком. Таким образом, термин "зависимый от приложения" более точно отражает функции так называемых коммутаторов четвертого уровня.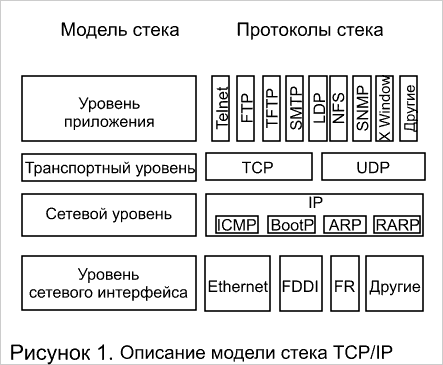
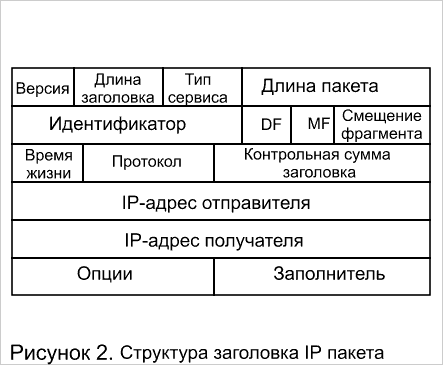
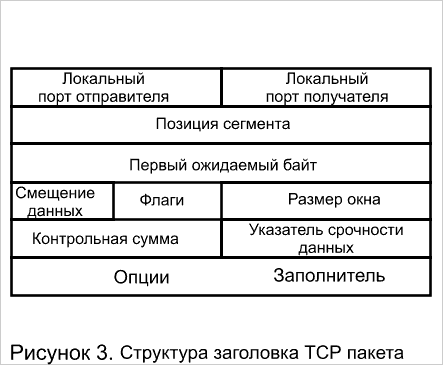
Тематики
EN
Англо-русский словарь нормативно-технической терминологии > switching technology
-
16 no matter how
1) Математика: как бы, как бы ни, как ни, сколь бы, сколь угодно, безразлично как (что, когда, где, кто, почему) (what, when, where, whether, who, why), независимо от того как (что, когда, где, кто, почему, что если) (what, when, where, who, why, whether)2) Патенты: независимо от того, как3) Макаров: как бы ни было -
17 alarm management
управление аварийными сигналами
-
[Интент]
Переход от аналоговых систем к цифровым привел к широкому, иногда бесконтрольному использованию аварийных сигналов. Текущая программа снижения количества нежелательных аварийных сигналов, контроля, определения приоритетности и адекватного реагирования на такие сигналы будет способствовать надежной и эффективной работе предприятия.Если технология хороша, то, казалось бы, чем шире она применяется, тем лучше. Разве не так? Как раз нет. Больше не всегда означает лучше. Наступление эпохи микропроцессоров и широкое распространение современных распределенных систем управления (DCS) упростило подачу сигналов тревоги при любом сбое технологического процесса, поскольку затраты на это невелики или равны нулю. В результате в настоящее время на большинстве предприятий имеются системы, подающие ежедневно огромное количество аварийных сигналов и уведомлений, что мешает работе, а иногда приводит к катастрофическим ситуациям.
„Всем известно, насколько важной является система управления аварийными сигналами. Но, несмотря на это, на производстве такие системы управления внедряются достаточно редко", - отмечает Тодд Стауффер, руководитель отдела маркетинга PCS7 в компании Siemens Energy & Automation. Однако события последних лет, среди которых взрыв на нефтеперегонном заводе BP в Техасе в марте 2005 г., в результате которого погибло 15 и получило травмы 170 человек, могут изменить отношение к данной проблеме. В отчете об этом событии говорится, что аварийные сигналы не всегда были технически обоснованы.
Широкое распространение компьютеризированного оборудования и распределенных систем управления сделало более простым и быстрым формирование аварийных сигналов. Согласно новым принципам аварийные сигналы следует формировать только тогда, когда необходимы ответные действия оператора. (С разрешения Siemens Energy & Automation)
Этот и другие подобные инциденты побудили специалистов многих предприятий пересмотреть программы управления аварийными сигналами. Специалисты пытаются найти причины непомерного роста числа аварийных сигналов, изучить и применить передовой опыт и содействовать разработке стандартов. Все это подталкивает многие компании к оценке и внедрению эталонных стандартов, таких, например, как Publication 191 Ассоциации пользователей средств разработки и материалов (EEMUA) „Системы аварийной сигнализации: Руководство по разработке, управлению и поставке", которую многие называют фактическим стандартом систем управления аварийными сигналами. Тим Дональдсон, директор по маркетингу компании Iconics, отмечает: „Распределение и частота/колебания аварийных сигналов, взаимная корреляция, время реакции и изменения в действиях оператора в течение определенного интервала времени являются основными показателями отчетов, которые входят в стандарт EEMUA и обеспечивают полезную информацию для улучшения работы предприятия”. Помимо этого как конечные пользователи, так и поставщики поддерживают развитие таких стандартов, как SP-18.02 ISA «Управление системами аварийной сигнализации для обрабатывающих отраслей промышленности». (см. сопроводительный раздел „Стандарты, эталоны, передовой опыт" для получения более подробных сведений).
Предполагается, что одной из причин взрыва на нефтеперегонном заводе BP в Техасе в 2005 г., в результате которого погибло 15 и получило ранения 170 человек, а также был нанесен значительный ущерб имуществу, стала неэффективная система аварийных сигналов.(Источник: Комиссия по химической безопасности и расследованию аварий США)
На большинстве предприятий системы аварийной сигнализации очень часто имеют слишком большое количество аварийных сигналов. Это в высшей степени нецелесообразно. Показатели EEMUA являются эталонными. Они содержатся в Publication 191 (1999), „Системы аварийной сигнализации: Руководство по разработке, управлению и поставке".
Начало работы
Наиболее важным представляется вопрос: почему так велико количество аварийных сигналов? Стауффер объясняет это следующим образом: „В эпоху аналоговых систем аварийные сигналы реализовывались аппаратно. Они должны были соответствующим образом разрабатываться и устанавливаться. Каждый аварийный сигнал имел реальную стоимость - примерно 1000 долл. США. Поэтому они выполнялись тщательно. С развитием современных DCS аварийные сигналы практически ничего не стоят, в связи с чем на предприятиях стремятся устанавливать все возможные сигналы".
Характеристики «хорошего» аварийного сообщения
В число базовых требований к аварийному сообщению, включенных в аттестационный документ EEMUA, входит ясное, непротиворечивое представление информации. На каждом экране дисплея:
• Должно быть четко определено возникшее состояние;
• Следует использовать терминологию, понятную для оператора;
• Должна применяться непротиворечивая система сокращений, основанная на стандартном словаре сокращений для данной отрасли производства;
• Следует использовать согласованную структуру сообщения;
• Система не должна строиться только на основе теговых обозначений и номеров;
• Следует проверить удобство работы на реальном производстве.
Информация из Publication 191 (1999) EEMUA „Системы аварийной сигнализации: Руководство по разработке, управлению и поставке".
Качественная система управления аварийными сигналами должна опираться на руководящий документ. В стандарте ISA SP-18.02 «Управление системами аварийной сигнализации для обрабатывающих отраслей промышленности», предложен целостный подход, основанный на модели жизненного цикла, которая включает в себя определяющие принципы, обучение, контроль и аудит.
Именно поэтому операторы сегодня часто сталкиваются с проблемой резкого роста аварийных сигналов. В соответствии с рекомендациями Publication 191 EEMUA средняя частота аварийных сигналов не должна превышать одного сигнала за 10 минут, или не более 144 сигналов в день. В большинстве отраслей промышленности показатели значительно выше и находятся в диапазоне 5-9 сигналов за 10 минут (см. таблицу Эталонные показатели для аварийных сигналов). Дэвид Гэртнер, руководитель служб управления аварийными сигналами в компании Invensys Process Systems, вспоминает, что при запуске производственной установки пяти операторам за полгода поступило 5 миллионов сигналов тревоги. „От одного из устройств было получено 550 000 аварийных сигналов. Устройство работает на протяжении многих месяцев, и до сих пор никто не решился отключить его”.
Практика прошлых лет заключалась в том, чтобы использовать любые аварийные сигналы независимо от того - нужны они или нет. Однако в последнее время при конфигурировании систем аварийных сигналов исходят из необходимости ответных действий со стороны оператора. Этот принцип, который отражает фундаментальные изменения в разработке систем и взаимодействии операторов, стал основой проекта стандарта SP18 ISA. В этом документе дается следующее определение аварийного сигнала: „звуковой и/или визуальный способ привлечения внимания, указывающий оператору на неисправность оборудования, отклонения в технологическом процессе или аномальные условия эксплуатации, которые требуют реагирования”. При такой практике сигнал конфигурируется только в том случае, когда на него необходим ответ оператора.
Адекватная реакция
Особенно важно учитывать следующую рекомендацию: „Не следует ничего предпринимать в отношении событий, для которых нет измерительного инструмента (обычно программного)”.Высказывания Ника Сэнд-за, сопредседателя комитета по разработке стандартов для систем управления аварийными сигналами SP-18.00.02 Общества ISA и менеджера технологий управления процессами химического производства DuPont, подчеркивают необходимость контроля: „Система контроля должна сообщать - в каком состоянии находятся аварийные сигналы. По каким аварийным сигналам проводится техническое обслуживание? Сколько сигналов имеет самый высокий приоритет? Какие из них относятся к системе безопасности? Она также должна сообщать об эффективности работы системы. Соответствует ли ее работа вашим целям и основополагающим принципам?"
Кейт Джоунз, старший менеджер по системам визуализации в Wonderware, добавляет: „Во многих отраслях промышленности, например в фармацевтике и в пищевой промышленности, уже сегодня требуется ведение баз данных по материалам и ингредиентам. Эта информация может также оказаться полезной при анализе аварийных сигналов. Мы можем установить комплект оборудования, работающего в реальном времени. Оно помогает определить место, где возникла проблема, с которой связан аварийный сигнал. Например, можно создать простые гистограммы частот аварийных сигналов. Можно сформировать отчеты об аварийных сигналах в соответствии с разными уровнями системы контроля, которая предоставляет сведения как для менеджеров, так и для исполнителей”.
Представитель компании Invensys Гэртнер утверждает, что двумя основными элементами каждой программы управления аварийными сигналами должны быть: „хороший аналитический инструмент, с помощью которого можно определить устройства, подающие наибольшее количество аварийных сигналов, и эффективный технологический процесс, позволяющий объединить усилия персонала и технические средства для устранения неисправностей. Инструментарий помогает выявить источник проблемы. С его помощью можно определить наиболее частые сигналы, а также ложные и отвлекающие сигналы. Таким образом, мы можем выяснить, где и когда возникают аварийные сигналы, можем провести анализ основных причин и выяснить, почему происходит резкое увеличение сигналов, а также установить для них новые приоритеты. На многих предприятиях высокий приоритет установлен для всех аварийных сигналов. Это неприемлемое решение. Наиболее разумным способом распределения приоритетности является следующий: 5 % аварийных сигналов имеют приоритет № 1, 15% приоритет № 2, и 80% приоритет № 3. В этом случае оператор может отреагировать на те сигналы, которые действительно важны”.
И, тем не менее, Марк МакТэвиш, руководитель группы решений в области управления аварийными сигналами и международных курсов обучения в компании Matrikon, отмечает: „Необходимо помнить, что программное обеспечение - это всего лишь инструмент, оно само по себе не является решением. Аварийные сигналы должны представлять собой исключительные случаи, которые указывают на события, выходящие за приемлемые рамки. Удачные программы управления аварийными сигналами позволяют добиться внедрения на производстве именно такого подхода. Они помогают инженерам изо дня в день управлять своими установками, обеспечивая надежный контроль качества и повышение производительности за счет снижения незапланированных простоев”.
Система, нацеленная на оператора
Тем не менее, даже наличия хорошей системы сигнализации и механизма контроля и анализа ее функционирования еще недостаточно. Необходимо следовать основополагающим принципам, руководящему документу, который должен стать фундаментом для всей системы аварийной сигнализации в целом, подчеркивает Сэндз, сопредседатель ISA SP18. При разработке стандарта „основное внимание мы уделяем не только рационализации аварийных сигналов, - говорит он, - но и жизненному циклу систем управления аварийными сигналами в целом, включая обучение, внесение изменений, совершенствование и периодический контроль на производственном участке. Мы стремимся использовать целостный подход к системе управления аварийными сигналами, построенной в соответствии с ISA 84.00.01, Функциональная безопасность: Системы безопасности с измерительной аппаратурой для сектора обрабатывающей промышленности». (см. диаграмму Модель жизненного цикла системы управления аварийными сигналами)”.
«В данном подходе учитывается участие оператора. Многие недооценивают роль оператора,- отмечает МакТэвиш из Matrikon. - Система управления аварийными сигналами строится вокруг оператора. Инженерам трудно понять проблемы оператора, если они не побывают на его месте и не получат опыт управления аварийными сигналами. Они считают, что знают потребности оператора, но зачастую оказывается, что это не так”.
Удобное отображение информации с помощью человеко-машинного интерфейса является наиболее существенным аспектом системы управления аварийными сигналами. Джонс из Wonderware говорит: „Аварийные сигналы перед поступлением к оператору должны быть отфильтрованы так, чтобы до оператора дошли нужные сообщения. Программное обеспечение предоставляет инструментарий для удобной конфигурации этих параметров, но также важны согласованность и подтверждение ответных действий”.
Аварийный сигнал должен сообщать о том, что необходимо сделать. Например, как отмечает Стауффер из Siemens: „Когда специалист по автоматизации настраивает конфигурацию системы, он может задать обозначение для физического устройства в соответствии с системой идентификационных или контурных тегов ISA. При этом обозначение аварийного сигнала может выглядеть как LIC-120. Но оператору информацию представляют в другом виде. Для него это 'регулятор уровня для резервуара XYZ'. Если в сообщении оператору указываются неверные сведения, то могут возникнуть проблемы. Оператор, а не специалист по автоматизации является адресатом. Он - единственный, кто реагирует на сигналы. Сообщение должно быть сразу же абсолютно понятным для него!"
Эдди Хабиби, основатель и главный исполнительный директор PAS, отмечает: „Эффективность деятельности оператора, которая существенно влияет на надежность и рентабельность предприятия, выходит за рамки совершенствования системы управления аварийными сигналами. Инвестиции в операторов являются такими же важными, как инвестиции в современные системы управления технологическим процессом. Нельзя добиться эффективности работы операторов без учета человеческого фактора. Компетентный оператор хорошо знает технологический процесс, имеет прекрасные навыки общения и обращения с людьми и всегда находится в состоянии готовности в отношении всех событий системы аварийных сигналов”. „До возникновения DCS, -продолжает он, - перед оператором находилась схема технологического процесса, на которой были указаны все трубопроводы и измерительное оборудование. С переходом на управление с помощью ЭВМ сотни схем трубопроводов и контрольно-измерительных приборов были занесены в компьютерные системы. При этом не подумали об интерфейсе оператора. Когда произошел переход от аналоговых систем и физических схем панели управления к цифровым системам с экранными интерфейсами, оператор утратил целостную картину происходящего”.
«Оператору также требуется иметь необходимое образование в области технологических процессов, - подчеркивает Хабиби. - Мы часто недооцениваем роль обучения. Каковы принципы работы насоса или компрессора? Летчик гражданской авиации проходит бесчисленные часы подготовки. Он должен быть достаточно подготовленным перед тем, как ему разрешат взять на себя ответственность за многие жизни. В руках оператора химического производства возможно лежит не меньшее, если не большее количество жизней, но его подготовка обычно ограничивается двухмесячными курсами, а потом он учится на рабочем месте. Необходимо больше внимания уделять повышению квалификации операторов производства”.
Рентабельность
Эффективная система управления аварийными сигналами стоит времени и денег. Однако и неэффективная система также стоит денег и времени, но приводит к снижению производительности и повышению риска для человеческой жизни. Хотя создание новой программы управления аварийными сигналами или пересмотр и реконструкция старой может обескуражить кого угодно, существует масса информации по способам реализации и достижения целей системы управления аварийными сигналами.
Наиболее важным является именно определение цели и способов ее достижения. МакТэвиш говорит, что система должна выдавать своевременные аварийные сигналы, которые не дублируют друг друга, адекватно отражают ситуацию, помогают оператору диагностировать проблему и определять эффективное направление действий. „Целью является поддержание производства в безопасном, надежном рабочем состоянии, которое позволяет выпускать качественный продукт. В конечном итоге целью является финансовая прибыль. Если на предприятии не удается достичь этих целей, то его существование находится под вопросом.
Управление аварийными сигналами - это процесс, а не схема, - подводит итог Гэртнер из Invensys. - Это то же самое, что и производственная безопасность. Это - постоянный процесс, он никогда не заканчивается. Мы уже осознали высокую стоимость низкой эффективности и руководители предприятий больше не хотят за нее расплачиваться”.
Автор: Джини Катцель, Control Engineering
[ http://controlengrussia.com/artykul/article/hmi-upravlenie-avariinymi-signalami/]Тематики
EN
Англо-русский словарь нормативно-технической терминологии > alarm management
-
18 not after
not until — только после того; как; только тогда; когда
lost or not lost — независимо от того, погиб груз или нет
not at any price — ни за что; ни при каких обстоятельствах
not so much sugar, please — не столько сахару, пожалуйста
-
19 biased multivibrator
ждущий мультивибратор
—
[Я.Н.Лугинский, М.С.Фези-Жилинская, Ю.С.Кабиров. Англо-русский словарь по электротехнике и электроэнергетике, Москва, 1999 г.]Тематики
- электротехника, основные понятия
EN
моностабильный элемент
одновибратор
-
[ГОСТ 2.743-91]Одновибраторы -"ждущие мультивибраторы" представляют собой микросхемы, которые в ответ на входной сигнал (логический уровень или фронт) формируют выходной импульс заданной длительности.
Длительность определяется внешними времязадающими резисторами и конденсаторами.
То есть можно считать, что у одновибраторов есть внутренняя память, но эта память хранит информацию о входном сигнале строго заданное время, а потом информация исчезает.
В стандартные серии микросхем входят одновибраторы двух основных типов:
- одновибраторы без перезапуска;
- одновибраторы с перезапуском
Одновибратор без перезапуска не реагирует на входной сигнал до окончания своего выходного импульса.
Одновибратор с перезапуском начинает отсчет нового времени выдержки Т с каждым новым входным сигналом независимо от того, закончилось ли предыдущее время выдержки.
В случае, когда период следования входных сигналов меньше времени выдержки Т, выходной импульс одновибратора сперезапуском не прерывается.
Если период следования входных запускающих импульсов больше времени выдержки одновибратора Т, то оба типа одновибраторов работают одинаково.
Одновибратор без перезапуска
Одновибратор с перезапуском
[Ю.В. Новиков. Введение в цифровую схемотехнику]
Параллельные тексты EN-RU
Monostable flip-flop
The output variable will be 1 only if the input variable changes to 1.
The output variable will remain 1 for 100 ms, regardless of the duration of the input value 1 (non-retriggerable).
Without a 1 in the function block, the monostable flip-flop is retriggerable.
The time is 100 ms in this example, but it may be changed to any other duration.
[Schneider Electric]Одновибратор
Значение переменной на выходе равно 1, если входная переменная становится равной 1.
Выходная переменная сохраняет значение 1 в течение 100 мс независимо от времени, в течение которого входная переменная продолжает оставаться равной 1 (без выполнения повторного запуска элемента).
Если в обозначении функции элемента не стоит "1", то это одновибратор с перезапуском.
В данном примере время выходного импульса составляет 100 мс, но его можно изменить на любое другое.
[Перевод Интент]Тематики
- Булева алгебра, элементы цифровой техники
Синонимы
EN
- biased multivibrator
- delay multivibrator
- gate multivibrator
- gated multivibrator
- kipp oscillator
- kipp relay
- latching circuit
- mono
- monoflop
- monostable
- monostable circuit
- monostable flip-flop
- monostable multivibrator
- monostable trigger circuit
- monovibrator
- one-cycle multivibrator
- one-shot
- one-shot generator
- one-shot multivibrator
- single flip-flop oscillator
- single vibrator
- single-shot flip-flop
- single-shot multivibrator
- single-shot trigger
- single-shot trigger circuit
- single-trip multivibrator
- single-trip trigger
- single-trip trigger circuit
- start-stop multivibrator
- trigger circuit
- univibrator
Англо-русский словарь нормативно-технической терминологии > biased multivibrator
-
20 gate multivibrator
ждущий мультивибратор
—
[Я.Н.Лугинский, М.С.Фези-Жилинская, Ю.С.Кабиров. Англо-русский словарь по электротехнике и электроэнергетике, Москва, 1999 г.]Тематики
- электротехника, основные понятия
EN
моностабильный элемент
одновибратор
-
[ГОСТ 2.743-91]Одновибраторы -"ждущие мультивибраторы" представляют собой микросхемы, которые в ответ на входной сигнал (логический уровень или фронт) формируют выходной импульс заданной длительности.
Длительность определяется внешними времязадающими резисторами и конденсаторами.
То есть можно считать, что у одновибраторов есть внутренняя память, но эта память хранит информацию о входном сигнале строго заданное время, а потом информация исчезает.
В стандартные серии микросхем входят одновибраторы двух основных типов:
- одновибраторы без перезапуска;
- одновибраторы с перезапуском
Одновибратор без перезапуска не реагирует на входной сигнал до окончания своего выходного импульса.
Одновибратор с перезапуском начинает отсчет нового времени выдержки Т с каждым новым входным сигналом независимо от того, закончилось ли предыдущее время выдержки.
В случае, когда период следования входных сигналов меньше времени выдержки Т, выходной импульс одновибратора сперезапуском не прерывается.
Если период следования входных запускающих импульсов больше времени выдержки одновибратора Т, то оба типа одновибраторов работают одинаково.
Одновибратор без перезапуска
Одновибратор с перезапуском
[Ю.В. Новиков. Введение в цифровую схемотехнику]
Параллельные тексты EN-RU
Monostable flip-flop
The output variable will be 1 only if the input variable changes to 1.
The output variable will remain 1 for 100 ms, regardless of the duration of the input value 1 (non-retriggerable).
Without a 1 in the function block, the monostable flip-flop is retriggerable.
The time is 100 ms in this example, but it may be changed to any other duration.
[Schneider Electric]Одновибратор
Значение переменной на выходе равно 1, если входная переменная становится равной 1.
Выходная переменная сохраняет значение 1 в течение 100 мс независимо от времени, в течение которого входная переменная продолжает оставаться равной 1 (без выполнения повторного запуска элемента).
Если в обозначении функции элемента не стоит "1", то это одновибратор с перезапуском.
В данном примере время выходного импульса составляет 100 мс, но его можно изменить на любое другое.
[Перевод Интент]Тематики
- Булева алгебра, элементы цифровой техники
Синонимы
EN
- biased multivibrator
- delay multivibrator
- gate multivibrator
- gated multivibrator
- kipp oscillator
- kipp relay
- latching circuit
- mono
- monoflop
- monostable
- monostable circuit
- monostable flip-flop
- monostable multivibrator
- monostable trigger circuit
- monovibrator
- one-cycle multivibrator
- one-shot
- one-shot generator
- one-shot multivibrator
- single flip-flop oscillator
- single vibrator
- single-shot flip-flop
- single-shot multivibrator
- single-shot trigger
- single-shot trigger circuit
- single-trip multivibrator
- single-trip trigger
- single-trip trigger circuit
- start-stop multivibrator
- trigger circuit
- univibrator
Англо-русский словарь нормативно-технической терминологии > gate multivibrator
См. также в других словарях:
Что? Где? Когда? — Эта статья о телевизионной игре. О турнирах и о спортивной версии игры см. Что? Где? Когда? (спортивная версия). Запрос «ЧГК» перенаправляется сюда; см. также другие значения. Что? Где? Когда? … Википедия
Что, где, когда — Что? Где? Когда? Эмблема телеигры: сова (символ мудрости) с короной Жанр телевизионная игра Автор Владимир Ворошилов Режиссёр Владимир Ворошилов (1975 2000) Борис Крюк (2001 наст. время) Производство … Википедия
Что, Где, Когда? — Что? Где? Когда? Эмблема телеигры: сова (символ мудрости) с короной Жанр телевизионная игра Автор Владимир Ворошилов Режиссёр Владимир Ворошилов (1975 2000) Борис Крюк (2001 наст. время) Производство … Википедия
Что-Где-Когда — Что? Где? Когда? Эмблема телеигры: сова (символ мудрости) с короной Жанр телевизионная игра Автор Владимир Ворошилов Режиссёр Владимир Ворошилов (1975 2000) Борис Крюк (2001 наст. время) Производство … Википедия
Что, где, когда? — Что? Где? Когда? Эмблема телеигры: сова (символ мудрости) с короной Жанр телевизионная игра Автор Владимир Ворошилов Режиссёр Владимир Ворошилов (1975 2000) Борис Крюк (2001 наст. время) Производство … Википедия
Что, Где, Когда — Что? Где? Когда? Эмблема телеигры: сова (символ мудрости) с короной Жанр телевизионная игра Автор Владимир Ворошилов Режиссёр Владимир Ворошилов (1975 2000) Борис Крюк (2001 наст. время) Производство … Википедия
Что?Где?Когда? — Что? Где? Когда? Эмблема телеигры: сова (символ мудрости) с короной Жанр телевизионная игра Автор Владимир Ворошилов Режиссёр Владимир Ворошилов (1975 2000) Борис Крюк (2001 наст. время) Производство … Википедия
Что Где Когда — Что? Где? Когда? Эмблема телеигры: сова (символ мудрости) с короной Жанр телевизионная игра Автор Владимир Ворошилов Режиссёр Владимир Ворошилов (1975 2000) Борис Крюк (2001 наст. время) Производство … Википедия
Что где когда — Что? Где? Когда? Эмблема телеигры: сова (символ мудрости) с короной Жанр телевизионная игра Автор Владимир Ворошилов Режиссёр Владимир Ворошилов (1975 2000) Борис Крюк (2001 наст. время) Производство … Википедия
Рассеянный склероз — Эту статью следует викифицировать. Пожалуйста, оформите её согласно правилам оформления статей. Рассеянный склероз … Википедия
ДЕТЕРМИНИЗМ И ИНДЕТЕРМИНИЗМ — (от лат. determino определяю, in не) две противоположные позиции по вопросу о взаимосвязи и взаимообусловленности явлений. Детерминизм (Д.) утверждает определяемость одних событий или состояний другими, Индетерминизм (И.) является отрицанием Д.… … Философская энциклопедия